Axolotl: Fine-Tune and Instruct-Tune LLMs with Ease
Axolotl is an easy-to-use framework for fine-tuning and instruction-tuning LLMs. It supports modern techniques like LoRA and quantization, and simplifies instruction-tuning with clear configuration options. Perfect for anyone looking to fine-tune LLMs without diving into complex code.

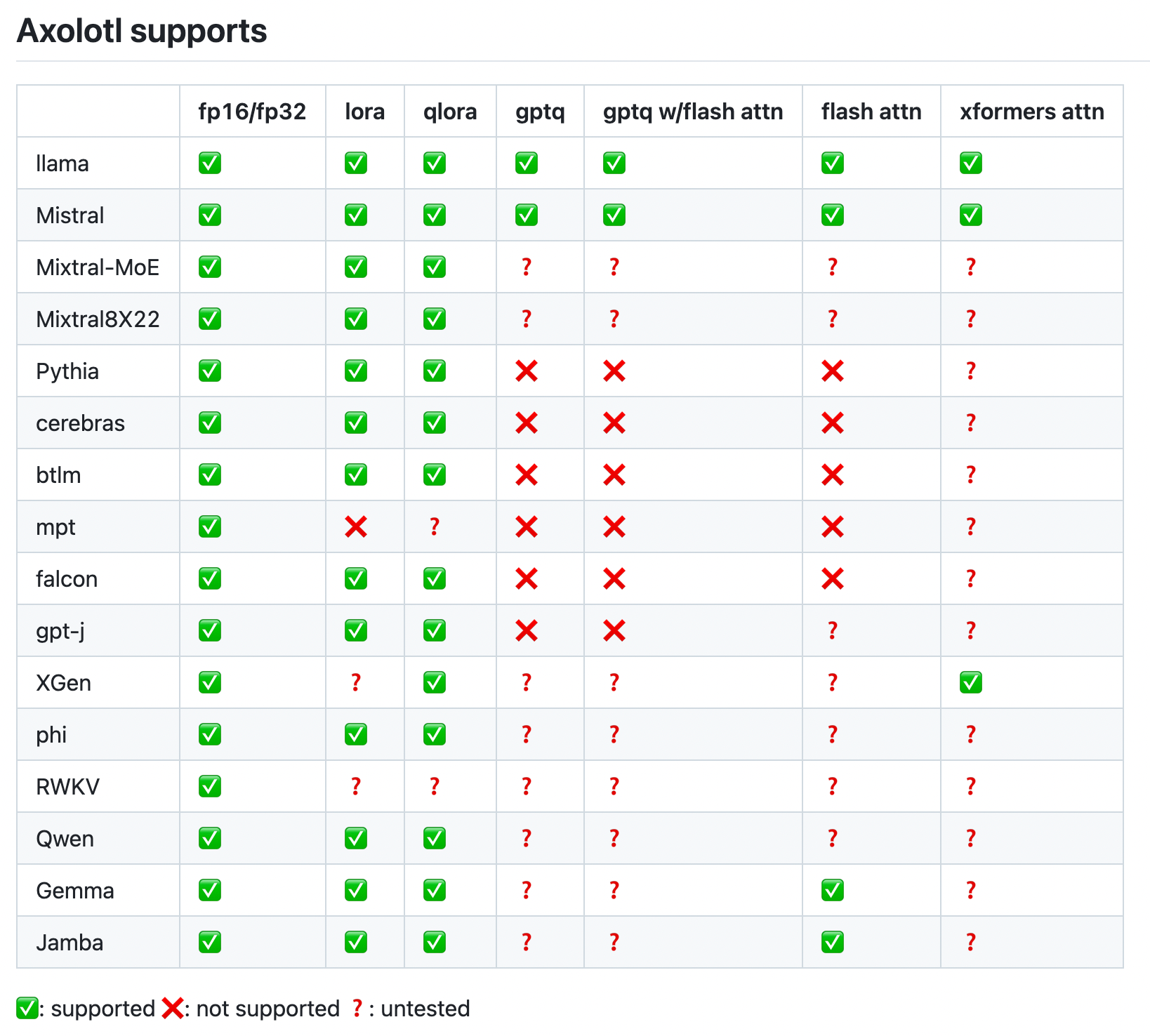
I've been using Axolotl for fine-tuning and instruction-tuning LLMs recently, and I'm really impressed with how straightforward it is.
While you could write your own training pipeline with HuggingFace and TRL, there are always little details that can get tricky, and you’ll probably end up copying a lot of code anyway. Axolotl makes things way simpler by supporting modern LLM training techniques right out of the box, including:
It supports modern LLM training techniques out of the box, including:
- LoRA/QLoRA for parameter-efficient fine-tuning
- 4-bit/8-bit quantization for memory-efficient training
- Multi-GPU training with Hugging Face Accelerate
For most tasks, you just need a basic configuration file—there are plenty of examples available—and then a few CLI commands, and you're good to go.
One feature I especially like is how Axolotl handles instruction-tuning. Often, you only want to apply the loss function to the completions (ignoring the instruction part of the prompt). Normally, if you’re writing this code yourself, you'd have to handle this carefully because of how tokenization works (e.g., as explained in this post).
On the other hand, Axolotl takes care of this automatically by supporting the input_output prompt construction, where you can explicitly mark segments where the loss function is applied by specifying "label": true, for example:
{
"segments": [
{
"label": true,
"text": "<s>Hello\n"
},
{
"label": true,
"text": "hi there!. "
},
{
"label": false,
"text": "goodbye "
},
{
"label": true,
"text": "farewell</s>"
}
]
}
One small caveat is that it doesn’t support bulk inference, which can be important when you’re evaluating your model on a dataset or benchmark. However, it’s relatively straightforward to write your own batch inference command by referring to the inference code.
Overall, Axolotl is a great tool for fine-tuning or instruction-tuning LLMs without getting bogged down in technical details. Definitely worth a try!