Evaluate Japanese LLMs with Ease: An All-in-One Framework
TL;DR: Discover llm-jp-eval, an easy-to-use framework for evaluating Japanese LLMs. This toolkit simplifies the process with standard datasets and nice configuration options, making LLM evaluation super easy—ideal for researchers and developers looking to benchmark LLMs quickly and effectively.

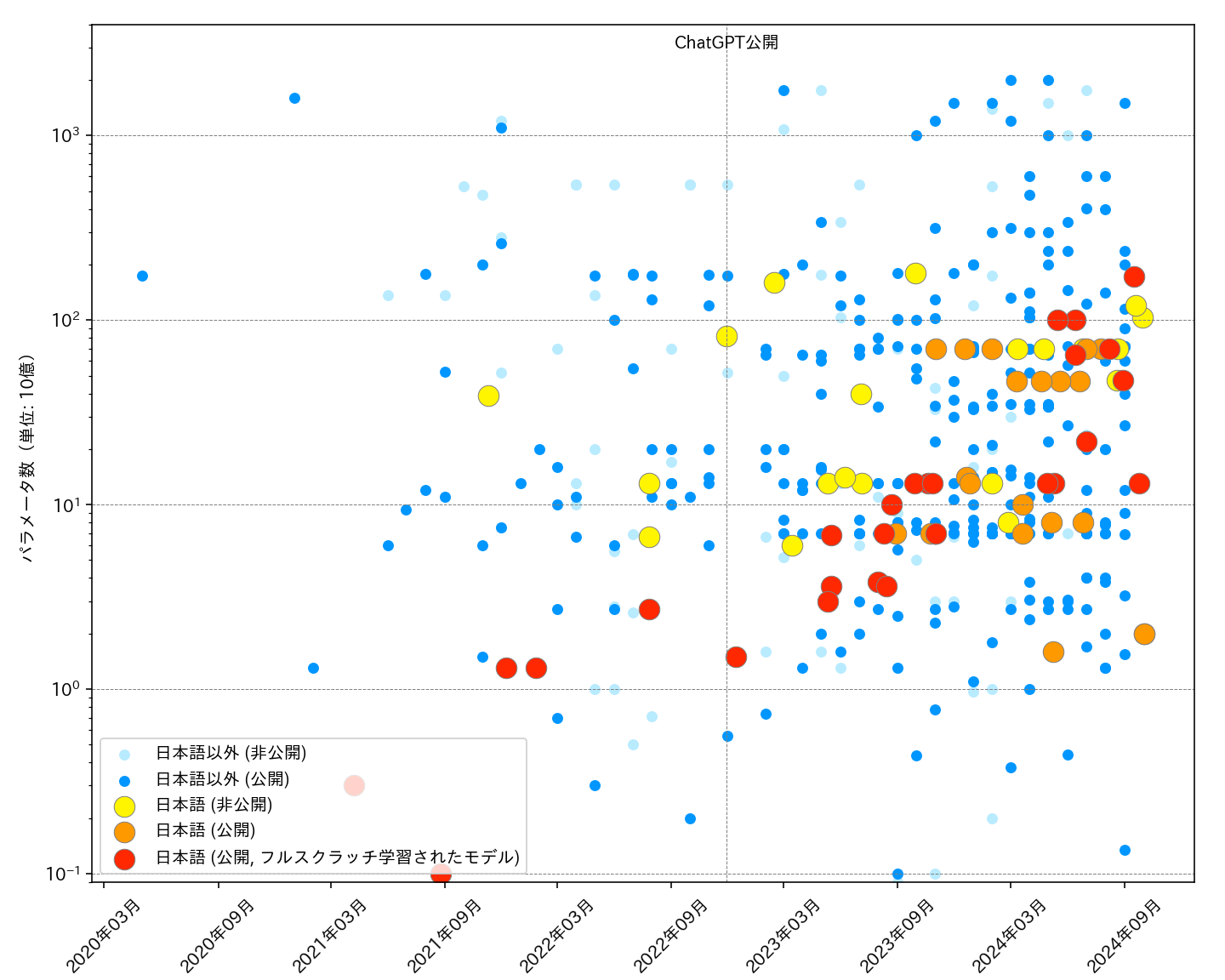
I've been investigating and catching up with the latest trends in Japanese LLMs and their evaluations, for reasons I'll detail in future posts.
Overall information regarding the latest trends in Japanese LLMs is really well summarized in this Github repository, awesome-japanese-llm. It seems like an extensive effort just to keep this updated, as it includes the latest models, benchmarks, and datasets.
One of the standout tools I discovered during my research on Japanese LLMs is the evaluation framework llm-jp-eval developed and maintained by the LLM-jp project. This framework is essentially a collection of scripts that make it straightforward to evaluate the performance of LLMs on various Japanese datasets. Here are a few highlights:
- It includes preprocessing scripts for a wide range of Japanese evaluation datasets, converting them into a standardized format.
- It offers user-friendly evaluation scripts with a nice configuration system that evaluates an LLM across multiple datasets seamlessly.
- Additional features include easy-to-configure few-shot learning, predefined evaluation metrics, offline inference compatibility with engines like vLLM and support for WandB monitoring.
The framework is well-structured, maintained, and extremely easy to use. After installation and dataset download, running an evaluation is as simple as executing a command. For example, if you want to evaluate the llm-jp/llm-jp-3-13b model (one of the latest Japanese LLMs) on the jcommonsenseqa dataset, you can simply run:
python scripts/evaluate_llm.py \
-cn config.yaml \
target_dataset=jcommonsenseqa \
dataset_dir=/path/to/datasets \
model.pretrained_model_name_or_path=llm-jp/llm-jp-3-13b \
tokenizer.pretrained_model_name_or_path=llm-jp/llm-jp-3-13b
The evaluation results will be saved in the logs directory.
Supported Datasets
By default, it supports many Japanese evaluation datasets, including:
- JSQuAD — Reading comprehension
- JAQKET (AIO) — Free-text question answering
- JCommonsenseQA — Multiple-choice question answering
- Japanese-English Bilingual Corpus of Wikipedia's Kyoto Articles — JA<->EN Machine translation
- XL-Sum (Japanese sub-dataset) — Text summarization
The platform uses a common dataset format, like the following example:
{
"instruction": "質問を入力とし、回答を出力してください。回答の他には何も含めないことを厳守してください。",
"output_length": 15,
"metrics": [
"char_f1"
],
"few_shots": [
{
"input": "質問:映画『ダイ・ハード』と『デッドプール2』のうち、公開年が早いほうはどっち?",
"output": "ダイ・ハード"
},
{
"input": "質問:東海旅客鉄道と北海道旅客鉄道はどちらも陸運業ですか?",
"output": "YES"
},
...
],
"samples": [
{
"input": "質問:クイーンとビートルズはどちらもイギリス出身のバンドですか?",
"output": "YES"
},
{
"input": "質問:東京都中央区と中野区、2005年時点での昼間人口が多いのは中央区ですか?",
"output": "YES"
},
...
]
}
If you have a custom dataset you'd like to evaluate, you can easily convert it to this common format without writing new inference or evaluation code.
Extending Beyond Japanese
Despite the framework's focus on Japanese datasets and models, the platform's core functionality is language-agnostic. If you have a different LLM and dataset, you can use this framework with minor adjustments, making it an excellent choice for evaluation across languages and domains. Highly recommended for anyone in the field!